New research from Mohamed bin Zayed University reveals what actually matters when building production AI agents. Spoiler: it's not the model.
- Why only 2% of Claude Code is AI reasoning, and what the other 98% actually does
- The five values that should drive every architectural decision in an AI system
- Why production AI failures are almost always harness failures, not model failures
- How to build a deny-first permission model that keeps humans in control
- The long-term skill atrophy risk nobody is tracking, and how to counter it
I built systems at scale. I've optimized cloud spend, managed teams, shipped products. The pattern I kept noticing is this:
Everyone obsesses over the model. Which LLM? What version? How many tokens? Bigger model = better AI, right?
Wrong. And new research just proved it.
A paper from Mohamed bin Zayed University of Artificial Intelligence analyzed the architecture of Claude Code, Anthropic's coding agent that can edit files, run shell commands, and iterate on tasks autonomously. Their headline finding:
Only ~1.6% of the codebase is AI decision logic. The other ~98.4% is operational infrastructure: permissions, context management, execution safety, recovery, and state persistence.
(The 1.6% figure comes from a community analysis of the extracted source. The point isn't the exact ratio. It's how thin the model-reasoning layer is compared to everything around it. This article uses "2%" throughout, a deliberate round for readability. The measured figure is ~1.6%. The order of magnitude is what matters.)
One objection worth pre-empting: lines of code is a crude proxy. The reasoning layer is architecturally dense, the core loop that processes tool calls, manages turn transitions, and routes decisions is doing disproportionate work per line compared to permission boilerplate or state logging. The 2% is real by volume, but the reasoning layer punches above its weight. The point still holds: most production failures trace back to harness failures, not model failures. A better model doesn't fix a broken permission system or a context assembly bug.
This changes how you should think about building AI systems. Not just at Anthropic scale. At yours.
The Insight That Changes Everything
The instinct is understandable. AI feels like magic. So we assume:
- Better model = better results
- Smarter reasoning = fewer problems
- More capability = more value
But the actual breakdown tells a different story.
Claude Code is roughly 98% operational harness: the infrastructure that determines whether the system is usable, safe, and reliable. The "pure" AI reasoning layer is the smallest part of the codebase.
Why? Because production AI agents don't fail because the model is dumb. They fail because:
- The system allowed an action the human didn't authorize
- Context wasn't loaded correctly, so reasoning was based on incomplete information
- Recovery failed and the loop couldn't recover gracefully
- The human interface didn't surface what the AI was about to do
- One bad output cascaded into system failure
None of those are model problems. They're architecture problems.
This is the insight that should reshape your AI strategy.
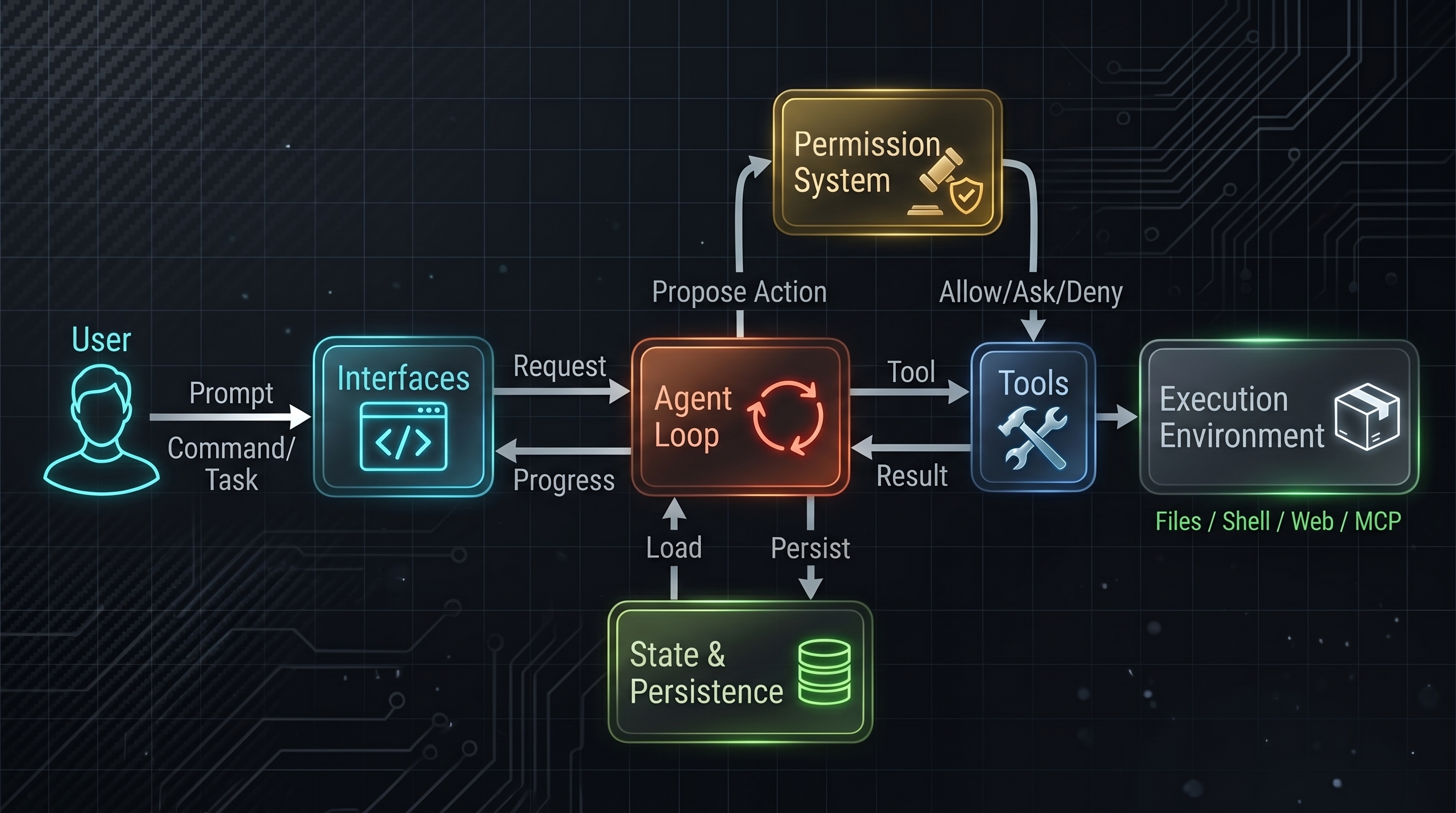
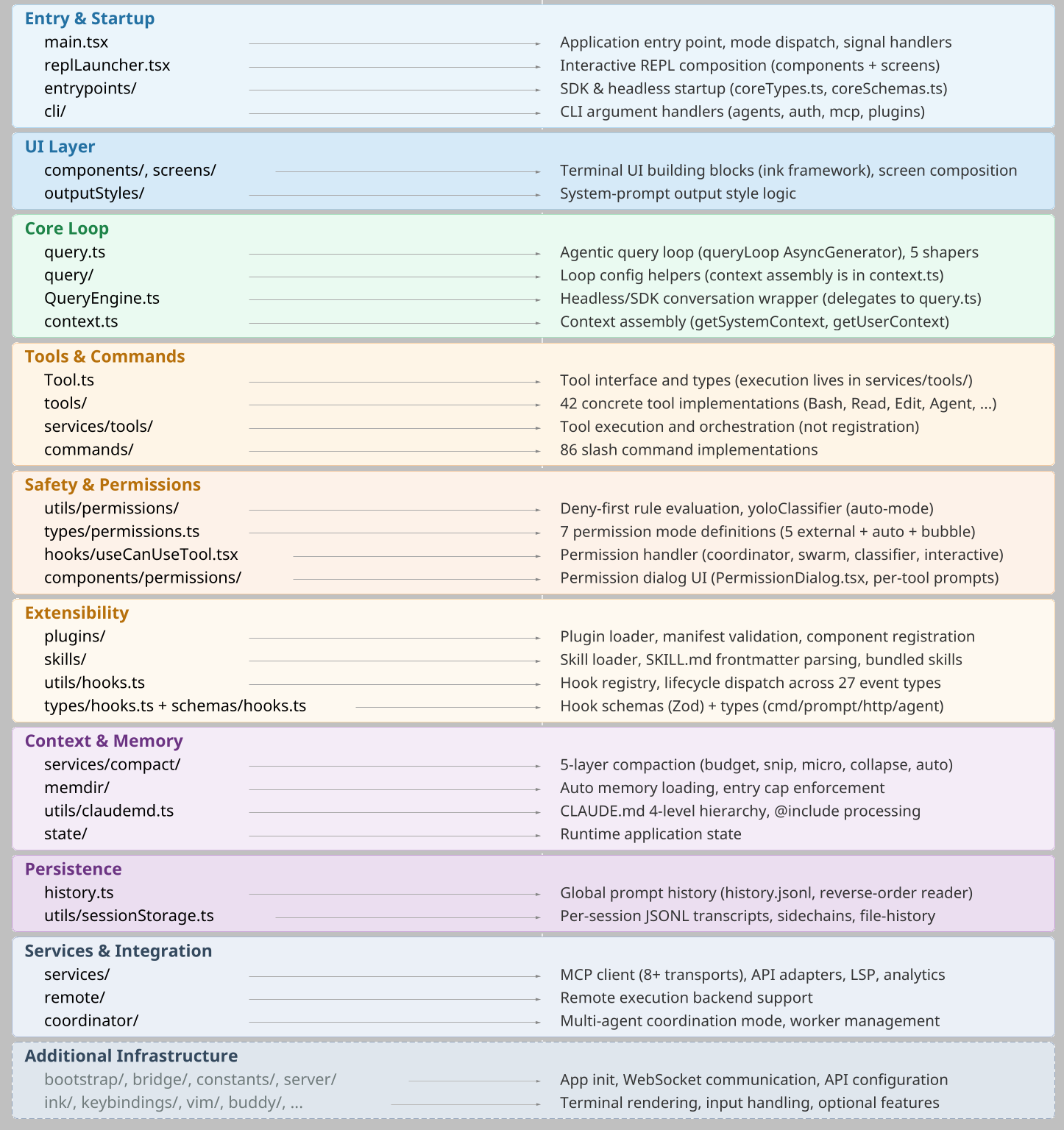
What Is "Harness" and Why It Matters
Harness is every system around the AI that makes it production-grade. Think of it as the skeleton that holds up the capability:
- Permission system: Which actions are allowed? Who decides? How do you prevent unauthorized escalation?
- Context management: What information does the AI see? How much? In what order? (Claude Code uses a five-layer compaction pipeline just for this.)
- Tool orchestration: How do you translate AI reasoning into actual system commands? How do you validate them first?
- Recovery mechanisms: When (not if) something goes wrong, what happens? Can the system recover? Who intervenes?
- State persistence: How does the system remember what happened across sessions? How do you prevent memory corruption?
- Execution safety: Can one bad action kill the whole system? How do you isolate failures?
This is where 98% of engineering effort goes. Not because the model is weak. Because production systems are hard.
The model is 2%. Everything else is engineering.
The Five Values That Drive Architecture
The research identifies five human values that motivate the entire architecture. These aren't nice-to-haves. They're design constraints that reshape every decision:
- Human Decision Authority - Humans retain ultimate control. The system proposes; humans approve or reject.
- Safety, Security, Privacy - The system protects humans and infrastructure from harm, even when the human makes a mistake.
- Reliable Execution - What the human intended actually happens. Consistently. Across context windows and sessions.
- Capability Amplification - The system makes humans more powerful, not a bottleneck.
- Contextual Adaptability - The system adjusts to your workflow, tools, and skill level. The relationship improves over time.
Every architectural decision traces back to one or more of these values. Permission layers → Human Authority + Safety. Context windows → Reliable Execution + Capability. CLAUDE.md hierarchy → Contextual Adaptability + Human Authority.
Start here. These values define what "production-grade" means for your system.
1. Human Decision Authority
The principle: Humans make the final call. The AI proposes; the human approves or rejects.
This sounds obvious. It's not. The temptation is to automate the approval away. "If the AI's confidence is above 95%, just execute." But Anthropic's own auto-mode analysis found that users approve roughly 93% of permission prompts, strong evidence of approval fatigue. The response wasn't to hide more approvals. It was to restructure: define the boundaries inside which the agent can work freely, and enforce safety independent of human vigilance.
Why? Because humans get tired. And tired humans make bad decisions. The system can't rely on attention as a safety mechanism.
How to implement it:
Don't rely on user approval as your only safety gate. Instead, define sandboxes that constrain actions, then enforce safety inside those boundaries. Human approval is ONE layer, not the only layer. Multiple independent checks mean approval fatigue doesn't collapse the system.
The insight: never make human vigilance your primary safety mechanism. Use it as the final gate after all automated checks have passed. This respects human authority without relying on constant human attention.
2. Safety, Security, Privacy
The principle: The system protects humans and infrastructure from harm, even when the human is inattentive or makes a mistake. This is distinct from authority: authority is about who decides; safety is about the system's obligation to protect.
Claude Code implements this as "deny-first with layered mechanisms." Seven independent safety checks gate every action. Any single one can block. If one layer fails silently, the others still apply:
- Tool pre-filtering: blanket-denied tools are stripped from the model's view before any call. The model never even tries.
- Deny-first rule evaluation: deny rules always win, even if a more specific allow rule exists.
- Permission mode constraints: the active mode (plan, default, acceptEdits, auto, dontAsk, bypassPermissions) sets the baseline for anything not matching an explicit rule.
- Auto-mode ML classifier: when enabled, classifies tool safety and can deny requests the rule system would have allowed.
- Shell sandboxing: Bash/PowerShell can run in a sandbox that restricts filesystem and network access, independent of permission state.
- Permission state not restored on resume: session-scoped permissions are deliberately dropped on resume or fork, so trust doesn't silently leak across sessions.
- Hook-based interception: PreToolUse hooks can deny, ask, or rewrite a tool call before execution.
Why seven layers? Because any single layer can fail silently. A bug in the classifier doesn't kill the system; the sandbox catches it. A misbehaving hook doesn't cascade, because pre-filtering has already excluded the most dangerous tools.
How to implement it:
Build a safety pipeline where each stage is independent: deny-first rule evaluation, ML classifier as gatekeeper, execution sandbox, and post-execution audit. Each stage must independently pass or the action is denied. Failure in one stage doesn't cascade to others.
The implementation principle: each safety layer must be independent and operable in isolation. If layer 3 fails, layers 1, 2, 4, and 5 still apply.
3. Reliable Execution
The principle: The system does what the human intended. Consistently. Across sessions. Without silent failures or drift.
This is harder than it sounds. AI can reason beautifully about what you want, then fail to execute it because:
- Context wasn't assembled correctly, so the AI had incomplete information on iteration 2
- Tool output was ambiguous, so the next iteration diverged from intent
- Session restarted and the AI forgot the original goal
- The recovery mechanism kicked in but chose a different strategy
Claude Code solves this through several mechanisms:
- Append-only durable state - Every action is logged. You can always rewind.
- Three-phase loop - Reason → Take action → Verify result. The verify phase catches divergence early.
- Context assembly hierarchy - System prompt, CLAUDE.md, project rules, then user context. Later layers don't override earlier ones arbitrarily.
- Graceful recovery - When errors happen, retry with degradation. If full context fails, retry with compact context. Never silent failure.
How to implement it:
Use a three-phase loop with verification: Reason → Execute → Verify. During the verify phase, catch divergence early. If verification fails, retry with degraded context or alternative strategy. Always log the full execution trace (append-only) so you can recover from any failure.
The implementation principle: three-phase loops beat single-pass execution. Verification catches divergence. Append-only logs let you recover from any failure.
4. Capability Amplification
The principle: The system materially increases what humans can accomplish per unit of effort and cost.
This is easy to measure: how much work got done that wouldn't have been attempted without the AI? Anthropic's internal survey (132 engineers and researchers) found that approximately 27% of Claude Code-assisted tasks were work that would not have been attempted without the tool: too time-consuming, too complex, or too error-prone to do manually. That's not faster work. That's qualitatively new work.
But capability amplification isn't automatic. You have to design for it:
- Context availability matters - If the AI can't see your project structure, your conventions, your constraints, it can't amplify your capability. It just wastes your time.
- Feedback loops matter - If the AI doesn't learn from corrections, from feedback, from your preferences, it stays at baseline capability.
- Tool availability matters - If the AI can only reason but not act, it's a thought experiment, not an amplifier.
How to implement it:
Capability amplification requires three elements: context richness (project structure, conventions, prior corrections), tool availability (the ability to read, write, execute), and feedback integration (learning from corrections and user preferences). The amplification multiplier comes from combining all three.
The implementation principle: capability amplification is context + tools + feedback. None alone is enough.
5. Contextual Adaptability
The principle: The system fits your specific context. Your project. Your tools. Your skill level. Your constraints. And this relationship improves over time.
This is why CLAUDE.md exists. It's a plain-text instruction file Claude Code reads from your project. Not just instructions. A declaration of your context: your values, your constraints, your patterns. The AI learns them and adapts.
Research shows this matters: in Claude Code, auto-approve rates climb from ~20% in users with fewer than 50 sessions to over 40% by 750+ sessions. The system is learning what you want and requiring less confirmation over time.
This is contextual adaptability in action: as the paper puts it, the system is "co-constructed by the model, the user, and the product."
How to implement it:
Build adaptive context in layers: organization defaults, user preferences, project-specific rules, session learning, and real-time feedback. Each layer refines earlier ones; later layers don't override them arbitrarily. The system learns through every interaction: edits, corrections, and approvals. Trust builds over time as the system consistently adapts to your context.
The implementation principle: context is hierarchical. Later layers don't override earlier ones; they refine them. And the system learns from every interaction.
How These Values Become Architecture
The five values don't just guide philosophy. They translate into specific design principles. The research identifies 13 of them:
- Deny-first with human escalation - Unrecognized actions are blocked, not allowed silently.
- Graduated trust spectrum - Permission levels evolve from plan-all-ask-all to auto with high confidence.
- Defense in depth - Multiple independent safety boundaries. No single point of failure.
- Externalized programmable policy - Rules live in config files, not hardcoded. You can change them without rebuilding.
- Context as bottleneck - Context window is the bounding constraint. Design around it, not pretending it doesn't exist.
- Append-only durable state - Never mutate history. Only add. Enables recovery and auditability.
- Minimal scaffolding, maximal operational harness - Less framework magic. More explicit infrastructure that you can reason about.
- Values over rules - Rigid procedures don't work. Contextual judgment backed by clear values does.
- Composable multi-mechanism extensibility: four independent extension surfaces (MCP servers for external tools, plugins for packaged bundles, skills for domain instructions, hooks for lifecycle events). Pick the right layer for your integration. Don't force everything into one mechanism.
- Reversibility-weighted risk assessment - Reversible actions can be more lenient. Read-only operations can auto-approve. Dangerous mutations need approval.
- Transparent file-based configuration - Users can see exactly what rules the AI operates under. Opaque databases break trust.
- Isolated subagent boundaries - Subagents have their own context and permissions. They don't break into parent context.
- Graceful recovery and resilience - When (not if) something fails, recover silently. If unrecoverable, escalate cleanly.
These aren't abstract ideas. They're the 98% harness that makes the 2% AI model actually work in production.
Case Study: The Permission System
Let's zoom in on one critical subsystem: permissions. This single layer implements multiple design principles and deserves detailed attention because it's where most real-world AI systems fail.
Claude Code implements seven independent permission modes:
- plan - User approves every action before it runs.
- default - Standard interactive mode. Most operations require approval.
- acceptEdits - Edits to working directory auto-approve. Other actions still ask.
- auto - ML classifier evaluates safety. High-confidence safe actions auto-execute.
- dontAsk - No prompts, but deny rules still enforce.
- bypassPermissions - Minimal prompts, but safety-critical checks enforce.
- bubble - Internal mode for subagent escalation to parent.
Notice the spectrum: from completely interactive (plan) to minimal prompts (bypassPermissions), but no mode removes safety checks entirely. The deny rules are always enforced, regardless of mode.
Why this architecture?
Because approval fatigue is real. If every action requires a prompt, users stop reading them. So the system doesn't try to protect through attention. Instead:
- Define a sandbox of what's allowed (deny rules)
- Let the AI operate freely within that sandbox
- Require approval only when the AI wants to step outside the sandbox
This respects human authority (humans define the sandbox) while respecting human attention (no approval fatigue).
How to build a similar permission system:
Start with Step 1: define categorically denied actions (rm -rf /, sudo passwd root, external ssh, etc.). Step 2: pre-filter tools by these rules so dangerous actions never enter the model's view. Step 3: define permission modes as escalation levels (plan: ask all, default: ask most, acceptEdits: dangerous only, auto: classifier decides). Step 4: graduated trust, where approval rate increases over time based on session count and classifier confidence. The key insight is that approval is graduated, not binary. Deny rules are independent of approval status and always enforced.
The implementation principle: Separate deny rules (hard boundaries) from approval gates (soft confirmation). Deny rules are always enforced. Approval gates can be graduated, but they're never the only safety mechanism.
When to Use AI vs. When Not To
Here's the most honest insight from the research: AI should amplify human capability, not replace human judgment.
This means some tasks are AI-good, others are AI-bad:
AI is good for:
- Tasks where you have clear criteria for success (write a test, refactor this code, document this function)
- Exploratory work (what does this codebase do? where should we optimize?)
- Repetitive work (apply the same pattern 47 times)
- High-effort, low-stakes decisions (naming, structure, comment generation)
AI is bad for:
- Tasks requiring true judgment (should we hire this person? do we ship this feature?)
- Tasks where failure is catastrophic and unrecoverable (financial transactions, medical decisions, access control)
- Tasks where you don't have criteria for success yet (is this the right architecture?)
- Tasks requiring accountability (signing contracts, making commitments)
The research shows this clearly: Claude Code excels at amplification tasks (write code, run tests, explore repos) but includes multiple safeguards for anything close to authority (executing shell commands, accessing sensitive files, committing changes).
Decision framework for when to use AI:
Evaluate five criteria: does the task have clear success criteria? Is it repetitive? Is the cost of failure low? Does it require judgment? Can it be retried safely? Use AI with confirmation gate if the first three are true and the last two are false. Use AI without confirmation only if all five criteria align strongly. Use AI with human-in-loop for exploratory work with clear criteria. For judgment calls or high-cost failures, use humans as the lead with AI as a research assistant only. Skip AI entirely if criteria don't align.
The principle: Use AI to amplify humans. Never use AI to replace judgment.
Implementation Guide: Three Patterns
Based on the research, here are three architectural patterns you can use in your own AI systems:
Pattern 1: The Deny-First Permission Model
Don't ask "is this allowed?" Start with "is this explicitly denied?" and work backwards. Step 1: does the action match a deny rule? If yes, block it. Step 2: does it match a safer sub-case of a deny rule? If yes, allow with audit. Step 3: no deny rule match. Now evaluate permission mode. In "plan" mode, ask the user. In "auto" mode, use ML classifier with a threshold. In "acceptEdits" mode, allow edit operations. This separates safety (deny rules are always enforced) from autonomy (permission modes are graduated).
This separates safety (deny rules) from autonomy (permission modes). Safety is always enforced. Autonomy is graduated.
Pattern 2: Append-Only State with Three-Phase Loops
Every turn has three phases: reason, execute, verify. State is only appended, never mutated. For each phase, track the input, output, and any errors. After the verify phase, decide whether to stop, retry, or escalate. Always append to the audit log; never mutate state. This ensures you can always audit what happened, replay any turn, and recover from failure by re-running from a known state.
This pattern ensures you can always audit what happened, replay any turn, and recover from failure by re-running from a known state.
Pattern 3: Hierarchical Context with Lazy Loading
Context is loaded in layers: system prompt (always), project CLAUDE.md (if exists), recent files (on demand), compact summary (when context nears capacity), and code search (on explicit request). Earlier layers take precedence; later layers refine them. Expensive operations are deferred until needed. Strict ordering ensures earlier layers don't get overridden by later ones arbitrarily. This keeps context small and responsive while ensuring you can access more detail when needed.
This pattern keeps context small and responsive while ensuring you can always access more detail when needed. Lazy loading prevents the context window from bloating with unused information.
The Long-Term Risk Nobody Talks About
The research identifies one structural risk that matters as AI systems scale. Two findings sit side by side in the paper:
Anthropic's internal survey of 132 engineers (Huang et al., 2025) documents a "paradox of supervision": overreliance on AI risks atrophying the very skills needed to supervise it. Independent research from Shen and Tamkin (2026) finds that developers working in AI-assisted conditions score 17% lower on comprehension tests (a single study with a limited sample, replication is early, but the mechanism is plausible enough to design against).
This is the real risk of AI amplification.
When you use AI to amplify your capability, you gain speed. But you may lose depth. The AI handles context management, so you don't learn how your system actually works. The AI refactors code, so you don't practice refactoring. The AI writes docs, so you don't think through explanation.
This isn't a reason to avoid AI. It's a reason to be intentional about it.
Principles for preventing skill atrophy:
- Review everything the AI produces, even when it's correct. You're not verifying quality; you're maintaining understanding.
- Do the hard parts yourself sometimes. Don't automate refactoring 100% of the time. Do it manually 20% of the time to stay sharp.
- Teach others using AI output. If you're explaining what the AI did, you're forced to understand it.
- Keep a "no AI" mode for critical systems. Some core logic should be written by humans, without AI assistance. This serves two purposes: it keeps the skill alive, and it gives you a human-only version to compare against if AI output diverges.
- Ask the AI to explain, not just execute. Don't just use the AI's code. Make it explain why it chose that approach. This keeps you learning.
The architecture of the harness protects you from external risk (safety, security, reliability). But it doesn't protect you from internal risk: your own skill degradation.
That's on you. The system should amplify, not replace.
The parallel risk, what accumulates in the codebase itself when AI generates without structural guardrails, is the subject of The Hidden Cost of AI-Generated Code. Same problem, external face.
Frequently Asked Questions
What is the 2% problem in AI systems?
Research from Mohamed bin Zayed University found only ~1.6% of Claude Code's architecture is AI reasoning logic. The other ~98.4% is operational harness: permissions, context management, tool orchestration, recovery mechanisms, and state persistence. Production AI systems fail almost exclusively due to harness failures, not model failures. The point is not the exact ratio. It is how thin the reasoning layer is compared to everything holding it up.
What does AI harness mean in practice?
The harness is everything around the model that makes it production-grade: the permission system (which actions are allowed and who can approve them), context management (what the AI sees and in what order), tool orchestration (translating AI reasoning into actual system commands safely), recovery mechanisms (what happens when something fails), and state persistence (how the system maintains memory across sessions without corruption).
How do I build a deny-first permission model?
Start with all permissions denied by default. Add explicit allow rules for specific, scoped actions only, never broad categories. Structure every rule as: what tool, what scope, what conditions. Never approve based on stated intent alone; always approve based on the specific action being requested. The goal is to make the permission layer the safety mechanism, not the human reviewer who has to catch every edge case.
How do I measure whether my AI harness is working?
Three signals: (1) Auto-approval rate stabilizing around 40–50%, not climbing toward 100%, which would indicate the permission model is becoming permissive by default. (2) False-positive rate on permission prompts below 10%, prompts that consistently fire but are always approved indicate misconfigured rules, not good safety. (3) Zero silent failures in production, every tool call should be logged and verifiable after the fact.
What is skill atrophy and how do I prevent it?
Skill atrophy is the gradual decline in a developer's ability to perform tasks they routinely delegate to AI. Research by Shen and Tamkin (2026) found developers in fully AI-assisted conditions scored 17% lower on code comprehension tests than peers in mixed-mode conditions, a single study with limited sample size, but a signal worth tracking. Prevention: deliberately practice core skills without AI assistance, maintain code review standards that require genuine understanding (not rubber-stamp approval), and track comprehension quality alongside output volume.
The Takeaway
The insight is simple but profound: production AI isn't about smarter models. It's about better harness.
If you're building an AI system:
- Spend 2% on the model. Spend 98% on everything else: permissions, context, safety, recovery, state management.
- Define your values first (human authority, safety, reliability, capability, adaptability). Design every architectural decision around them.
- Build deny-first permission models. Never rely on approval as your only safety mechanism.
- Use append-only state with three-phase loops. Reason, execute, verify. Always. No shortcuts.
- Hierarchical context with lazy loading. Load system context first, then project context, then on-demand context. Let expensive operations defer.
- Use AI to amplify humans. Know when not to use it. Track skill atrophy and counter it intentionally.
The 2% AI is impressive. But it's the 98% harness that makes it actually work.
Build the harness first. The model follows.
Further Reading
Original research paper: "Dive into Claude Code: The Design Space of Today's and Future AI Agent Systems" - Mohamed bin Zayed University, April 2026
From the paper, the design principles that matter most:
- Section 2.1: Five human values that drive architecture
- Section 3: Architecture overview and component decomposition
- Section 4: The query loop (three-phase reasoning, execution, verification)
- Section 5: Permission and safety layers
- Section 6: Extensibility mechanisms (MCP, plugins, skills, hooks)
- Section 7: Context construction and memory management
Working through the challenges in this post? I help engineering leaders and CTOs navigate complex technical decisions and scale high-performing teams. Schedule a consultation →