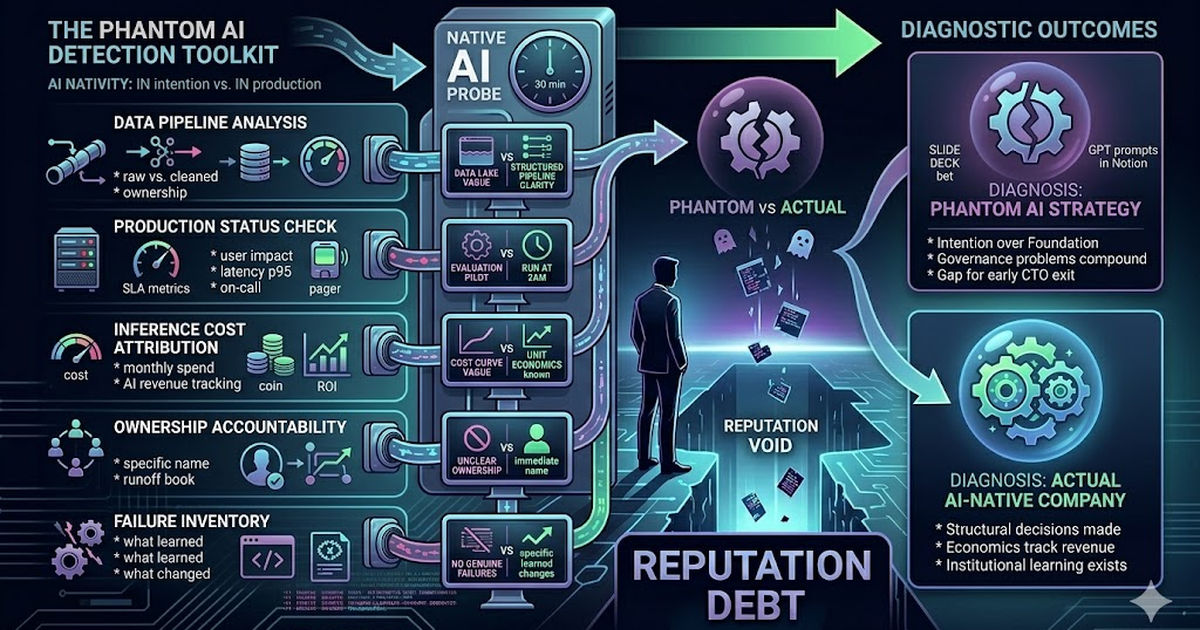
A detection toolkit for CTOs evaluating companies to join, investors doing technical due diligence, and boards who want to know whether the AI roadmap is real before they fund the next round.
GenAI adoption jumped from 33% to 71% of companies in a single year. Revenue from it didn't. And according to MIT's NANDA initiative, whose 2025 study The GenAI Divide: State of AI in Business drew on 150 executive interviews, a survey of 350 employees, and analysis of 300 public AI deployments, roughly 95% of generative AI pilots are failing to reach production.
Those two numbers exist simultaneously. More companies than ever are calling themselves AI-first. Fewer than you'd expect have anything in production that moves a business metric.
I sat in 30+ CTO interviews this year. Every company was AI-first. Most of them had a slide about it. A few had a dedicated head of AI on the org chart. One had a roadmap that stretched to 2028 with impressive detail about features that depended on AI systems that hadn't been built yet.
Maybe eight of those companies were actually AI-native.
The difference shows up within 30 minutes if you know what to ask. Not "what's your AI strategy?" - that question gets you the slide deck. The questions that reveal which category a company falls into are narrower, more specific, and almost no one asks them in a standard interview process.
This is the detection toolkit I developed across those 30+ conversations. Use it before you accept an offer. Use it before you write a cheque. Use it in your next board meeting.
The Gap No One Talks About in Interviews
Most companies describing themselves as AI-first fall into one of two categories.
The first: companies that have made structural decisions. They have data infrastructure that predates the AI roadmap. They have models in production with real inference costs, SLAs, and named owners. They have a list of failed experiments - and they can tell you what those experiments cost, what the hypothesis was, and what they changed as a result. They have engineers who have been paged at 2am because an AI system failed in production.
The second: companies doing what I call phantom AI strategy. They have the language of AI-first without the foundations. The roadmap exists as a slide. The data exists as a vague reference to a data lake. The AI initiative exists as an "exploration" - which often means someone shared a collection of GPT prompts in a Notion document, ran a few demos, and filed it under strategy.
Phantom companies are not lying, exactly. They believe the roadmap. They intend to build the infrastructure. They are genuinely excited about what AI will do for the business. But the gap between intention and foundation is where CTOs get hired into impossible situations, burn out inside 18 months, and leave with a gap on their resume and a story they can only tell privately.
A strategy is what you intend. A system is what you run at 2am when it breaks. These are not the same thing, and the interview process almost never asks you to tell the difference.
The five questions below are designed to find that gap before you accept the offer - or before you sign the term sheet.
The 30-Minute Diagnostic
Ask these questions in sequence. Most phantom companies reveal themselves by question two. Genuinely AI-native companies will answer all five without notes, without hesitation, and with the kind of specific frustration that only comes from having actually run these systems in production.
# The 30-minute AI-native diagnostic# Ask in sequence. Stop early only if answers are already solid.
questions: - id: data ask: > Walk me through your data pipeline. What does the data look like before it reaches a model? phantom_tells: - "We have a lot of data" - "We use BigQuery / Snowflake / Redshift" - "We're working on data quality" [no owner, no timeline] native_signals: - Named source systems with known schemas and latencies - Specific quality problems and the person responsible for them - "We tried X but our event stream wasn't granular enough"
- id: production ask: > Which AI systems are in production right now, serving real users, with SLAs you own? phantom_tells: - "We're in pilot with a few teams" - "We're evaluating a few options" - "We use ChatGPT for [internal workflow]" [web interface, not API] native_signals: - A model name or version, even approximate - A latency target they've measured and sometimes miss - A named on-call rotation for when AI systems fail
- id: costs ask: > What do you spend on inference per month? How does that track against AI-driven revenue? phantom_tells: - "We're still working on measuring ROI" - "It's early, we're not tracking that yet" - "It's not a significant cost right now" [without knowing the number] native_signals: - A specific number, even a rough order of magnitude - "We spend about X per active session and it's trending down" - A view on what happens when subsidized model pricing normalizes
- id: ownership ask: > Who gets paged if the AI systems are down at 2am on a Tuesday? phantom_tells: - [visible pause] "...we're still figuring out the ownership model" - "Probably ML, or maybe the platform team" - Reference to someone who left the company 4 months ago native_signals: - A name. Not a team. A specific person. - A runbook, even an informal one - An escalation path that does not end with "it depends"
- id: failures ask: > Tell me about an AI initiative that didn't work. What happened? phantom_tells: - "We haven't really failed yet - we're still early" - Description of a pilot that was quietly discontinued - "We're being careful not to ship things prematurely" native_signals: - A specific system, a specific failure mode, a specific cost - What the team decided: fix it, rebuild it, or shut it down - "Here is what changed in how we build AI systems after that"Save this. Adapt it for your context. The questions look simple because the tells are simple. Companies that haven't built real AI systems can't answer questions about running real AI systems.
Question 1: Ask About the Data, Not the Model
This is the question almost no one asks in an interview: "Walk me through your data pipeline - what does the data look like before it gets to a model?"
The reason this question lands differently is that most AI conversations start with the model. Which model are you using? Are you considering GPT-4o or Claude? Have you evaluated Gemini? These are not bad questions, but they're the wrong questions first. Models are commodities. Data is not.
AI-native companies answer the data question immediately and specifically. They tell you which systems produce data, how often, in what format, what the quality problems are, and who owns the resolution of those problems. Crucially, they know the difference between data they have and data they wish they had. That distinction matters: it only exists if someone has actually tried to build something and hit the wall.
The tells for phantom companies are consistent across conversations:
- "We have a lot of data" - volume is not strategy. What format? From where? Updated how often?
- "We use BigQuery" - having a warehouse is not having a data strategy. Everyone has a warehouse.
- "We're working on data quality" - fine if followed by a named owner and a timeline. Almost never is.
The underlying truth hasn't changed since the first machine learning project anyone ever shipped: AI doesn't fail at the model layer. It fails at the data layer. Companies that don't know what their data looks like before it reaches a model don't have an AI strategy. They have an AI intention. Those are very different things to inherit as an incoming CTO.
Question 2: Production vs. Evaluation
The question: "Which AI systems are currently in production, serving real users, with SLAs you're responsible for?"
The word "production" does significant work here. Production means: it breaks at 2am and someone gets paged. It means latency SLAs. It means monitoring, alerting, fallback behavior, and rollback procedures. It means the system generates or protects revenue and someone is accountable when it doesn't.
AI-native companies answer with operational specifics. A model name or version. A latency target - p95 or p99 - that they've measured and know they occasionally miss. A fallback behavior when the model is unavailable. A cost per request they've actually instrumented. They tell you about an incident, usually with a specific date attached.
Phantom companies answer with tense and pronoun problems. Note the difference:
| Phantom language | AI-native language |
|---|---|
| "We're planning to ship this in Q3" | "We've been running this in prod since February" |
| "We're exploring what's possible" | "We tried [X], it underperformed, we switched to [Y]" |
| "We're in pilot with the sales team" | "Sales uses it for every outbound - about 400 calls a week" |
| "We use ChatGPT internally" | "We're on Claude via API with a custom system prompt and a cost cap per user" |
| "The timeline depends on hiring" | "We need to solve the latency problem - we're at 800ms p95 and the target is 400ms" |
The pilot trap is real and common. A pilot serving 12 internal users with no SLA, no monitoring, and no rollback plan is not a production system. It is a demo with a longer timeline. A new CTO walking into a pilot and calling it production will spend their first six months explaining to the board why the AI roadmap has slipped by a year.
Question 3: The Inference Cost Question
The question: "What do you spend on inference per month, and how does that track against your AI-driven revenue?"
This question is uncomfortable for a reason. It requires someone to have built two things simultaneously: cost instrumentation and revenue attribution. Most companies have done neither. Building cost-per-feature tracking for AI systems requires engineering effort that feels non-urgent until the bill arrives. Building AI-driven revenue attribution requires a business model clear enough to connect specific systems to specific outcomes.
AI-native companies know the number. They might not love sharing it in an interview, but they know it - even if it's approximate. More importantly, they know whether the economics are working. They have a view on the cost curve and whether it's improving. They've thought about what happens to their unit economics when the current generation of subsidized model pricing normalizes.
That last point matters more in 2026 than it did in 2023. The inference pricing models from the major labs have been artificially low, supported by the competitive dynamics of the model wars. Companies that have built their AI product economics on today's pricing without a plan for normalized costs are carrying a structural risk they haven't accounted for. The companies that know their inference cost per unit of output are the ones who will survive that transition.
"We're working on measuring ROI" means they've been spending without knowing the return. Which means no one has required the measurement. Which means the AI initiative exists outside the company's economic accountability structure. That is not a small problem to walk into.
A CTO who joins a company without this measurement in place will spend their first six months building it. That is not always the wrong choice - green-field infrastructure problems can be interesting - but it's worth knowing in advance that you're signing up for it rather than the AI product roadmap that was described in the interview.
Question 4: Ask Who Owns It
The question: "Who is accountable if the AI systems are down for four hours on a Tuesday afternoon?"
In AI-native companies, the answer is immediate and specific. A name. A team. A runbook. An escalation path. The question doesn't create discomfort because the structure already exists and someone has already been paged for this exact scenario.
In phantom companies, the question creates a visible pause followed by a discussion. Would it be the ML team or the platform team? Do they have an ML team yet? Is this a product responsibility or an infrastructure responsibility? The company that hasn't answered this question hasn't actually shipped AI systems - because the first time a production AI system fails, the ownership question gets answered very loudly and very publicly.
Unclear ownership of AI systems is not a technical problem. It's a governance problem. Governance problems compound: they get harder to resolve as systems get more embedded in the product, as more teams depend on them, and as the political cost of changing the structure increases. A new CTO walking into unclear AI ownership will spend significant political capital resolving something that should have been settled before the first system shipped.
The follow-up question worth asking: "Has that person ever actually been paged for this?" The answer tells you whether the ownership is real or theoretical.
Question 5: The Failure Inventory
The question: "Tell me about an AI initiative that didn't work. What happened?"
This is the most diagnostic question on the list, and the one most interviewers skip because it feels negative. It shouldn't. Failures are evidence of iteration. A company that has been experimenting seriously for 18 months has a failure inventory. They can tell you which approaches didn't work, what the hypothesis was, what the actual outcome was, and - critically - what they changed in how they build AI systems as a result of the failure.
Phantom companies answer this question in one of two ways. Either: "We haven't really failed - we're still early" (which means they haven't shipped enough to generate a real failure). Or: they describe a pilot that was quietly discontinued, which is not the same thing.
A genuine AI failure has a specific shape:
- Something was in production - real users, real traffic
- It broke or underperformed against a defined expectation
- Users were affected in a measurable way
- The team had to make a decision: fix it, rebuild it, or shut it down
- Something changed in how they work as a result
If no one in the interview can describe that sequence, the company has not been running AI systems seriously enough to generate that experience. That's the diagnostic. You cannot fake a failure inventory.
The follow-up that separates good from exceptional: "What changed in how you build AI systems after that?" A company that answers both questions has genuine institutional learning. That is rare, and it's the most positive signal you'll encounter in a due diligence process.
What the Language Tells You
After 30+ interviews, the language patterns separate within the first ten minutes. You don't need all five questions to know which category a company is in. You need to listen for the vocabulary.
Phantom AI companies use language that is aspirational, approximate, and future-tensed:
- "We're betting big on AI"
- "AI is central to our product vision"
- "We're exploring what's possible with the new models"
- "We want to add AI to every feature by the end of the year"
The words are large. The specifics are absent. Notice the tense: future or continuous present, never simple past. They are going to build. They are exploring. They have not shipped.
Real AI-native companies use language that is operational, constrained, and past-tensed:
- "We run three models in production - classification, generation, and ranking. The classification model has a 200ms p95 target and we miss it about 4% of the time."
- "We tried using embeddings for search. It didn't outperform BM25 for our corpus, so BM25 is still the primary signal."
- "The model we're most exposed to is our customer-facing summarization system. It costs us about £0.06 per session and we've brought it down from £0.11 over six months."
- "We had an incident in March where the model latency spiked to 4 seconds on p99. We added a synchronous fallback to the rule-based system. It's been stable since."
The specificity is the tell. Real AI-native companies don't describe their AI strategy. They describe their AI systems. Strategies are intentions. Systems are things that break at 2am. The vocabulary reflects which one actually exists.
Scoring the Answers
After 30+ conversations, I developed a simple mental model for scoring what I heard. Five questions, five points. Use it as a gut-check, not a hiring rubric.
| Question | What AI-native sounds like | Score |
|---|---|---|
| Data pipeline | Named source systems, specific quality problems, a named owner for each | +1 |
| Production systems | A model name or version, a latency target they sometimes miss, a named on-call | +1 |
| Inference costs | A specific monthly number or order of magnitude, and whether it's trending down | +1 |
| Ownership | A name - not a team. A runbook - not a meeting. An escalation path that ends somewhere. | +1 |
| Failure inventory | A specific failure, what the team decided, and what changed in how they build after it | +1 |
Reading the score: Five out of five is genuinely AI-native - rare, worth noting. Three or four means a real foundation at an early stage: you're building on something, not from nothing. Three is the threshold because it requires both foundational capabilities, data infrastructure and something in production, plus at least one operational discipline. In practice, the companies that reach 3 almost always have Questions 1 and 2 answered; the variability shows up in cost tracking, ownership clarity, and failure documentation. One or two is phantom strategy - the roadmap is the product, and the foundation work will land on the incoming CTO. Zero means the slide deck is the AI strategy, and the role being described in the interview does not yet exist.
A score of 0 or 1 is not automatically a reason to walk away. Some CTOs specifically want the green-field problem - building the AI foundation from scratch is genuinely interesting work. But you need to know that's what you're accepting before you accept it. Phantom strategy becomes a trap only when you mistake it for a foundation.
The companies worth joining are the ones that are honest about which score they have. A company that says "we're at a 2, we know it, and here's the plan to get to a 4" is more valuable than a company that performs a 5 in the interview and delivers a 1 on day one.
The companies worth avoiding are not the ones with low scores. They're the ones with low scores and high confidence. That combination - phantom strategy delivered with executive certainty - is where good CTOs disappear.
Sources:
- McKinsey (2024). "The State of AI in 2024." GenAI adoption 33% to 71% in one year.
- MIT NANDA Initiative (2025). The GenAI Divide: State of AI in Business. Based on 150 executive interviews, a survey of 350 employees, and analysis of 300 public AI deployments. Covered in: Fortune, August 2025. ~95% of GenAI pilots failing to reach production.
Working through the challenges in this post? I help engineering leaders and CTOs navigate complex technical decisions and scale high-performing teams. Schedule a consultation →