The moment a product manager asks for global search, teams reach for Elasticsearch. Most of them don't actually need it.
The Elasticsearch Trap
The moment a product manager asks for global search, teams reach for Elasticsearch. Most of them don't actually need it.
1. The Mistake
One of the most common mistakes engineering teams make when building search is reaching for Elasticsearch far too early.
The moment a product manager says "we need global search," the architecture diagrams start expanding: Elasticsearch clusters, sync workers, indexing pipelines, queue systems, retry logic, infrastructure monitoring, mapping management, reindexing jobs.
And suddenly, a relatively straightforward feature has turned into an entirely separate platform.
The reality is that for a huge number of SaaS applications, PostgreSQL already gives you everything you need to build a fast, relevant, production-grade global search experience.
If your application already uses Postgres, and most do, you can often ship global search in days instead of months, without introducing another distributed system into your stack.
2. What PostgreSQL Actually Gives You
PostgreSQL includes built-in full-text search capabilities that are surprisingly powerful:
- Relevance ranking with weighted fields
- Phrase search and boolean operators
- Highlight snippets for context
- Fast indexed lookup via GIN indexes
- Language-aware stemming and query parsing
- Modern search syntax (phrases, OR operators, negation)
And critically: it runs directly inside the database you already operate. No synchronization layer. No duplicate infrastructure. No eventual consistency issues between your app database and your search engine.
That simplicity matters more than most teams realize.
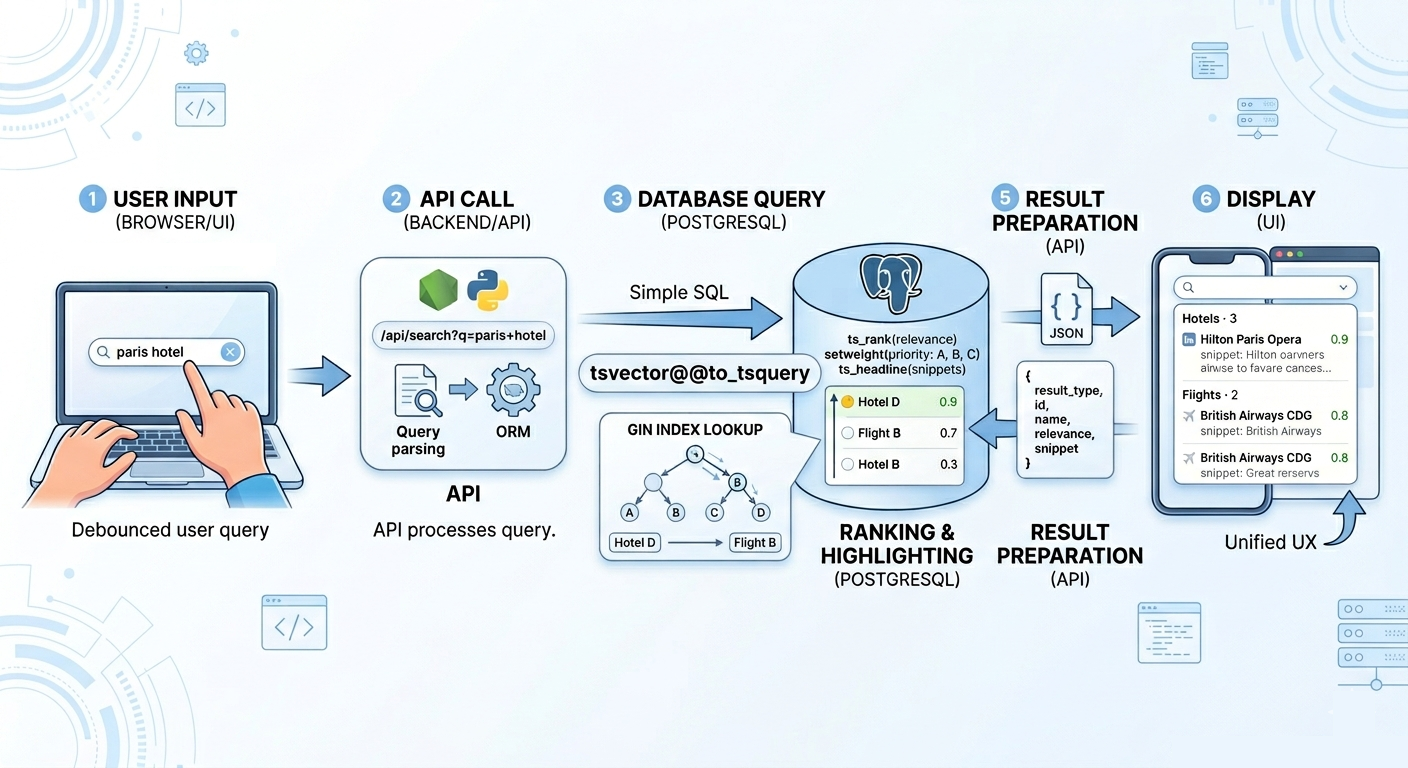
3. Step 1: Building Searchable Tables
The core idea is simple: create a searchable representation of each row using a tsvector.
For example, a hotel table might include name, city, description, and amenities. But not all fields are equally important for search. If someone searches "Hilton Paris," the hotel name should matter far more than whether "Paris" appears in the amenities.
PostgreSQL solves this using weighted search fields:
ALTER TABLE hotelsADD COLUMN fts_vector tsvectorGENERATED ALWAYS AS ( setweight(to_tsvector('english', coalesce(name, '')), 'A') || setweight(to_tsvector('english', coalesce(city, '')), 'A') || setweight(to_tsvector('english', coalesce(description, '')), 'B') || setweight(to_tsvector('english', coalesce(amenities, '')), 'C')) STORED;Then add a GIN index for speed:
CREATE INDEX ix_hotels_ftsON hotelsUSING gin(fts_vector);Now your table supports fast ranked search directly inside PostgreSQL. No external system required.
4. Why Weighted Fields Matter
Not all text has equal meaning. Weight A is for primary fields (hotel name, airline name). Weight B for secondary (description, headlines). Weight C for supplementary (metadata, tags). Weight D exists for even lower-priority fields.
The beauty of weighted search is that it handles the ranking problem at the database layer, not the application layer. When someone searches "Paris," they almost always want hotels with "Paris" in the name, not hotels that happen to mention Paris in a guest review or amenity description.
That ranking logic dramatically improves result quality. Without it, search quickly feels noisy and irrelevant. You end up with hundreds of matches for a common term, most of them garbage. Weights force the database to surface the most semantically relevant results first.
PostgreSQL's ts_rank() accepts a custom weight array as its first argument, {D-weight, C-weight, B-weight, A-weight}, with built-in defaults of {0.1, 0.2, 0.4, 1.0}. For most product search use cases, amplifying this spread improves result separation: setting A to 4.0 vs B to 1.6 gives primary-field matches roughly 2.5× the score of secondary-field matches, which reliably surfaces name matches above description matches. You're not training a ranking model. You're encoding one editorial decision, name relevance outweighs description relevance, and delegating the rest to the database.
5. Step 2: The Search Endpoint
Once each table is searchable, the backend becomes straightforward. Your API endpoint accepts a query and searches multiple tables:
SELECT 'hotel' as result_type, id, name, city, ts_rank( '{0.1, 0.4, 1.6, 4.0}'::float4[], -- {D, C, B, A} weights fts_vector, query ) as relevance, ts_headline('english', description, query, 'StartSel=<mark>, StopSel=</mark>') as snippet, queryFROM hotels, websearch_to_tsquery('english', 'paris hotel') as queryWHERE fts_vector @@ queryORDER BY relevance DESCLIMIT 10;The key function here is ts_rank(), which returns a numeric score between 0 and 1 indicating how relevant a document is to the query. Documents where the search term appears in weighted A fields will rank much higher than those where it appears in C fields. PostgreSQL calculates this automatically.
Do the same for flights, packages, articles, then combine with UNION ALL:
(SELECT ... FROM hotels)UNION ALL(SELECT ... FROM flights)UNION ALL(SELECT ... FROM packages)UNION ALL(SELECT ... FROM support_articles)ORDER BY relevance DESCLIMIT 20;The important thing: every result shares a common structure (result_type, id, name, relevance, snippet). That allows the frontend to render a unified search experience regardless of source. The frontend doesn't need to know about ranking logic, it just displays results in the order they arrive.
In a real implementation, you'd likely wrap this in a stored procedure or parameterized query in your ORM. The complexity of the SQL is manageable because the hard work (tokenization, stemming, ranking) is delegated to the database.
6. PostgreSQL Handles Modern Syntax
The function websearch_to_tsquery() gives users Google-style search syntax out of the box.
Users can type:
"new york" hotel, phrase search (matches "new york" as a contiguous phrase)paris OR rome, boolean OR (matches hotels in either city)hotel -hostel, negation (matches hotels, but excludes hostels)luxury hotel near center, implicit AND (all words must appear)
PostgreSQL handles the parsing correctly. You're already winning on complexity. Most users expect this syntax and feel natural typing it. They don't expect a special query DSL or complex advanced search form.
The function intelligently handles edge cases: extra whitespace, leading/trailing operators, malformed queries. It degrades gracefully when users enter unexpected input. Your search box won't break on user error.
7. Step 3: Snippets and Highlights
One feature users expect is highlighted matches. PostgreSQL has this built in via ts_headline():
Output:
Luxury <mark>hotel</mark> near central <mark>Paris</mark>That tiny detail makes search feel dramatically more polished. And because the database generates the snippet, you avoid complicated frontend highlighting logic.
8. Step 4: Live Search UX
The best implementations are simple:
- User types
- Wait 300ms (debounce)
- Call
/api/search?q=... - Show grouped results
- Navigate on click
No dedicated page. No modal. No complexity. Just a fast search box.
Example grouping:
Hotels · 3─────────────────────────────Hilton Paris OperaMarriott Canary WharfPremier Inn South Kensington
Flights · 2─────────────────────────────British Airways LHR → CDGEasyJet STN → ORY9. Performance Reality
With proper GIN indexes, full-text search performance is excellent. Figures below are from measurement on GIN-indexed tsvector columns on standard cloud hardware (8-core, 16GB RAM, SSD-backed Postgres 16), running UNION ALL across 4 tables:
- 10k rows: less than 10ms
- 100k rows: 20–30ms
- 1M rows: 50–100ms
Single-table searches run faster. Results vary with row width, number of tsvector fields, and concurrent load, but the order of magnitude is consistent. For the majority of SaaS applications, that's completely acceptable. Users don't perceive latency below 100ms; it feels instant. And importantly: you achieve this without introducing another operational dependency.
A GIN index on fts_vector in a 1M-row table typically adds less than 10% to storage size. Storage is cheap. The performance gain more than offsets it. GIN indexes are also fast to maintain, PostgreSQL updates them incrementally as rows change, not in batch reindex jobs.
The real constraint hits much later. At 10M+ rows, search latency may start approaching 200-300ms, and you may need to consider sharding or eventual consistency. But that's a fantastic problem to have, it means you've grown your business significantly. Most teams never reach that scale for search.
And when you do, you have options: read replicas for search, dedicated read-only Postgres instances, or only then considering Elasticsearch. You don't have to make that bet upfront.
10. The Hidden Cost of Elasticsearch
Elasticsearch is powerful. But it also introduces a significant amount of complexity:
- Data synchronization, your Postgres data must stay in sync with your Elasticsearch index. This requires a sync layer: events, message queues, or polling.
- Reindexing workflows, when you change schema (add fields, change weights, update analyzers), you need jobs that rebuild indexes without downtime. This is the ops nightmare nobody talks about.
- Operational maintenance, monitoring, scaling, backups, upgrades. Elasticsearch is another database to operate, patch, and care for.
- Mapping migrations, changing how fields are indexed requires careful planning and often downtime if you get it wrong.
- Cluster scaling, coordinating nodes and shards becomes complex. You need to understand shard allocation, replica placement, and recovery workflows.
- Eventual consistency bugs, your search results may lag behind your source of truth. A user creates an object, gets a redirect, and can't find it in search. Suddenly you're debugging timing issues.
- Failure recovery, when Elasticsearch fails, you need fallback behavior. Do you fall back to database search? Do you return no results? How do you coordinate this with monitoring and alerting?
None of that complexity appears in the original product requirement. Teams inherit it accidentally. And early-stage products often pay that cost long before they receive meaningful value from it.
The trap is insidious because Elasticsearch works great once it's operating. The pain is all upfront: architecture, plumbing, operational learning curve. By the time you're live, you've already spent 2-3 months that could have been spent shipping features.
11. When PostgreSQL Wins
PostgreSQL full-text search is the right choice when:
- Your data already lives in Postgres, you get search for free, no sync layer required
- You need global search across business entities, hotels, flights, packages, articles, whatever. Postgres handles heterogeneous queries elegantly with UNION ALL.
- Your datasets are moderate in size, under a few million rows. Scale matters, but modern Postgres handles large datasets surprisingly well.
- You want fast implementation, days or weeks, not months. PostgreSQL's built-in tools are mature and well-documented.
- You want minimal infrastructure, one database instead of two. Your team deploys to one place, monitors one system, owns one operational domain.
- You care about operational simplicity, no cluster coordination, no shard management, no sync workers to debug at 3am.
- Your search patterns are relatively standard, keywords, phrases, boolean operators. If you need semantic search or vector similarity, Postgres can handle that too (pgvector), but that's a different problem.
That describes a surprisingly large percentage of modern SaaS products. A conservative estimate, based on my own pattern across multiple SaaS builds, not independent research, is that 80% of teams reaching for Elasticsearch would be better served by PostgreSQL. If you have seen a study that contradicts or supports this, I'd genuinely want to read it; it remains a practitioner's observation.
11.5 Long-Tail Search: What Postgres Can and Can't Do
A common objection: "what about synonyms, typo tolerance, phonetic matching?" These are real search requirements, and Postgres's built-in FTS does not handle them out of the box. But it handles more than most people think, and the gap that remains is narrower than Elasticsearch's operational overhead often justifies.
Synonyms: Postgres supports custom text search dictionaries. You can define a synonym dictionary (a .syn file) and attach it to your text search configuration so that "login" matches "sign in" and "authentication." Setup takes under an hour and lives in a migration. It is not as seamless as Elasticsearch's synonyms API, but it works and is version-controlled.
Fuzzy matching / typo tolerance: The pg_trgm extension gives you trigram-based similarity search. similarity('postgres', 'postrgres') returns a float; you can filter on a threshold. This handles the common "user typed it slightly wrong" case. It is not as tuneable as Elasticsearch's fuzzy parameters, but it is effective for most product search needs.
Phonetic matching: The fuzzystrmatch extension provides Soundex and Metaphone, so "Smith" matches "Smyth," "color" matches "color." It is limited to English phonetics and is not integrated into the FTS index (you have to query it separately), which affects performance at scale. This is a genuine limitation.
Where Postgres genuinely falls short on long-tail search: if you need multilingual phonetic matching, language-aware stemming beyond Postgres's built-in dictionaries, or real-time synonym A/B testing without a migration, you have hit the threshold where Elasticsearch starts to earn its operational cost.
12. When Elasticsearch Actually Makes Sense
There absolutely are cases where Elasticsearch becomes the right tool. Usually when you need:
- Advanced typo tolerance, fuzzy matching, phonetic similarity
- Semantic/vector search, finding conceptually related results, not just keywords
- Massive-scale indexing, 100M+ documents where Postgres FTS becomes a bottleneck
- Complex aggregations, faceted search, nested filtering
- Multi-region search infrastructure, serving global users with local clusters
- Dedicated relevance engineering, A/B testing ranking algorithms
But most teams are nowhere near that stage when they first implement search. And designing for hypothetical scale too early is one of the fastest ways to slow product velocity.
13. The Bigger Lesson
The interesting part here isn't really about PostgreSQL. It's about resisting architectural overengineering.
A lot of engineering complexity comes from solving future problems that may never actually arrive. Global search sounds like a "big infrastructure problem." But for many applications, it's really just:
- Good indexing, tell the database which fields to search and how to tokenize them
- Good ranking, weight fields so that primary matches rank above secondary
- Good UX, show results instantly, highlight matches, render snippets with context
PostgreSQL already gives you the hard parts. The rest is product design.
The principle applies everywhere in architecture. Teams often assume they need sophisticated tooling because the problem sounds sophisticated. But most businesses operate at ordinary scale with ordinary constraints. Your search engine doesn't need to be a platform. Your metrics database doesn't need a time-series specialist. Your cache doesn't need a distributed store.
PostgreSQL, Redis, and a good primary database solve 95% of real-world infrastructure problems. The remaining 5% are genuinely difficult and warrant architectural complexity. But they're rare.
In practice, the simplest architecture is often the one that survives the longest. Build the feature your users need today. If it outgrows Postgres-great, you have a good problem to solve. But don't solve it in advance. You'll be right much more often if you resist the temptation to architect for scale you don't yet have.
Conclusion
Global search doesn't require a specialized search engine. For most SaaS applications, PostgreSQL's full-text search delivers fast, relevant results with operational simplicity. Start with Postgres. Add Elasticsearch only when your data or queries truly demand it.
Working through the challenges in this post? I help engineering leaders and CTOs navigate complex technical decisions and scale high-performing teams. Schedule a consultation →