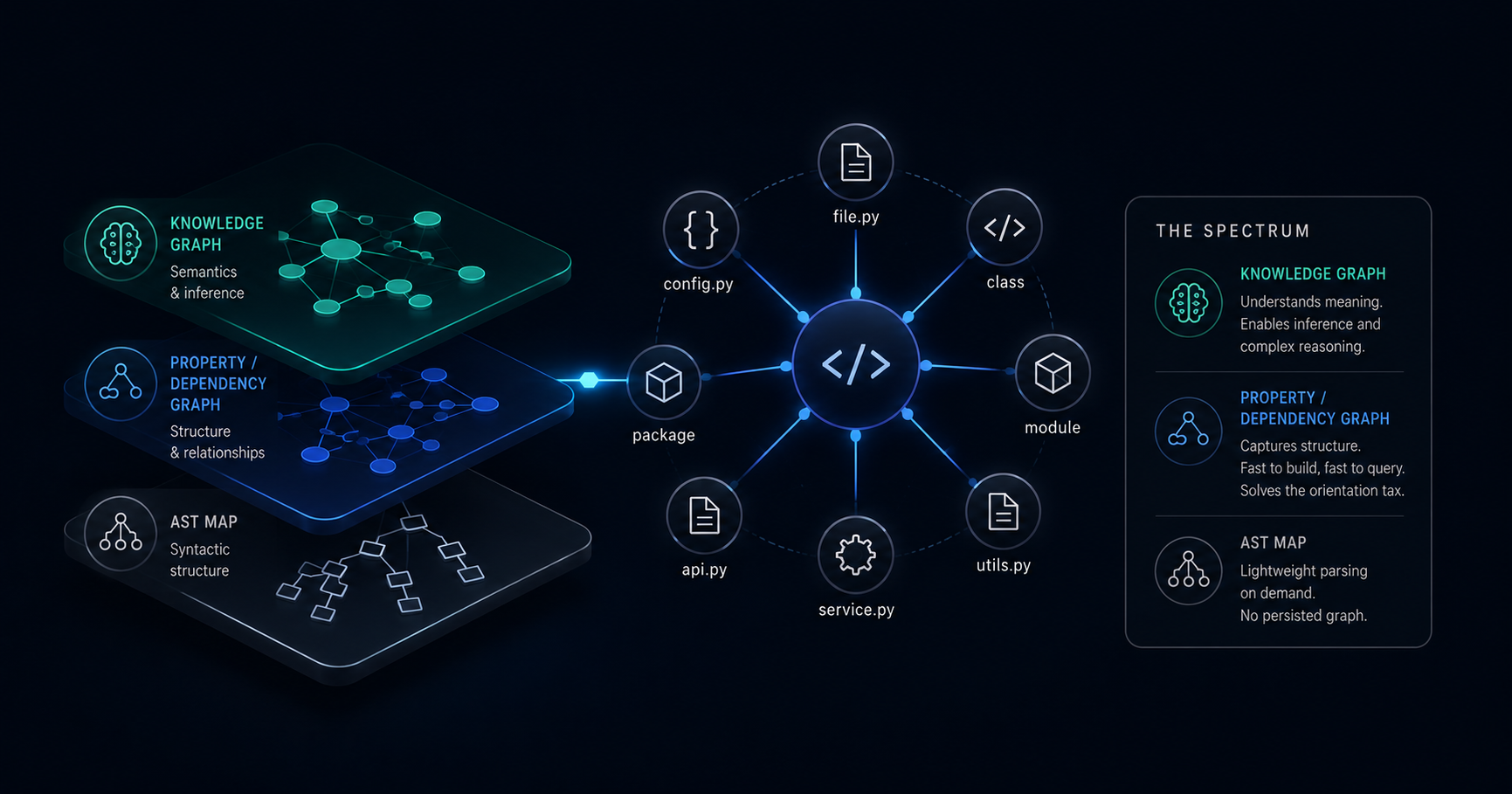
Most tools currently marketed as "knowledge graphs for AI coding" are not knowledge graphs. They are dependency graphs. That is not a criticism - dependency graphs are exactly what AI coding agents need for most structural questions. But the terminology confusion is concealing a real architectural choice that engineering teams are making without realizing it.
I noticed this because I have built three production knowledge graphs. The first was in 2019 with Grakn - typed schema, bidirectional relationships, inference rules. Then a custom Python stack with graph-tool and NetworkX when operational overhead became untenable. Then a Neo4j migration that found the balance between schema richness and practical query performance. Each step on that spectrum taught me something different about what graphs can and cannot do.
When the current wave of "AI coding graph tools" emerged, I looked at them differently than most. So I ran the experiments. This article documents what I found.
The Terminology Problem
The term "knowledge graph" has a specific meaning in the field. A true knowledge graph has typed nodes and edges, schema-level constraints, and typically supports inference - the ability to derive facts not explicitly stored. Neo4j with a defined ontology qualifies. Grakn (now TypeDB) qualifies. These systems let you ask questions like "find all patterns where a stateless function unexpectedly mutates shared state across three call layers" - because the schema encodes what "stateless" and "mutation" mean as typed concepts.
What most AI coding tools build is a property graph or dependency graph: nodes are code entities (files, classes, functions), edges are structural relationships (imports, calls, inherits). No inference. No schema enforcement. Fast to build, fast to traverse, sufficient for the most common AI coding context questions.
Below that sits the AST map: a lightweight structural index derived from tree-sitter parsing, computed per query rather than persisted. No stored graph at all - just structured parsing on demand.
The spectrum matters because it sets accurate expectations. A CTO who deploys a dependency graph tool expecting Grakn-style inference will be disappointed. A CTO who understands they are getting a fast, queryable structural index will use it correctly and get real value from it.
The Orientation Tax
Andrej Karpathy described context engineering as "the delicate art and science of filling the context window with just the right information for the next step." That framing identifies a structural problem most teams have not solved.
Every AI coding agent currently pays what I call an orientation tax: before answering a cross-file question, it reads files to establish context it should already have. Ask an agent to trace the data flow through a 200-file service - which modules call which, what the dependency chain looks like, where the integration points sit - and it either reads many files (expensive) or infers incorrectly (unreliable). This is not a model quality problem. It is a context primitive problem.
Files contain the what. They do not naturally contain the how things connect. Flat text is the wrong primitive for relational questions. And the majority of interesting questions about a production codebase are relational.
Graph-based context is the structural answer to this. Not a replacement for text - an index layer built above it that tells the agent which functions call which, which classes inherit what, and which modules are entangled, before a single file is opened.
The academic research on this is consistent. LocAgent (2025) achieved 92.7% file-level localization accuracy using graph-guided code traversal, with an 86% cost reduction versus proprietary models at comparable accuracy. Repository Intelligence Graph (RIG) showed a 12.2% overall accuracy improvement and 53.9% faster completion on multi-file tasks. These are not small margins.
The question is what the production tools deliver today - and vendor claims are not the right place to look for that answer.
What These Tools Actually Build
Before evaluating tools, the taxonomy matters. These three levels are meaningfully different:
True Knowledge Graph
Typed schema, inference rules, bidirectional semantic relationships. Examples: Neo4j with a defined ontology, TypeDB/Grakn. Supports complex semantic queries that require the system to reason about relationships, not just traverse them. Real engineering overhead - schema design, inference tuning, ongoing maintenance. Best suited for compliance-grade reasoning, cross-codebase semantic analysis, and architectural drift detection at scale.
Property Graph / Dependency Graph
Nodes are code entities (files, classes, functions, methods). Edges are structural relationships (imports, calls, inherits, references). No inference. Fast to build from AST parsing, fast to query. This is what Graphify, Sweep AI, and the LocAgent research pattern actually build. For AI coding context, this is usually sufficient - the orientation tax is a structural problem, and a structural index solves it.
AST Map
Derived from tree-sitter parsing on demand. No persisted graph. Aider's repo map is the canonical implementation - it uses a PageRank-scored tree-sitter parse to identify the most structurally important symbols in a codebase and passes them as a lightweight index. Continue.dev adds local embeddings (LanceDB) alongside AST parsing. Lightest weight option; works well for codebases under 200 files where graph construction overhead outweighs the benefit.
When a vendor says "knowledge graph," ask which level they are actually building. The answer changes what you can expect it to do.
The Tools Landscape
| Tool | What it actually builds | LLM integration | Self-hosted | License | Best for |
|---|---|---|---|---|---|
| Graphify | Property graph (AST + LLM semantic extraction) | Claude Code skill (/graphify), MCP | Yes | MIT | Large repos 500+ files, local-first |
| Sourcebot | Search index + natural language query layer | MCP server (BYOLLM) | Yes | Fair Source | Multi-repo search, enterprise scale |
| Sourcegraph Cody | Semantic code graph + BM25 (abandoned embeddings) | IDE extension | No (cloud) | Proprietary | Enterprise, cross-repo, IDE-native |
| Continue.dev | Local embeddings (LanceDB) + tree-sitter AST | IDE extension | Yes | Apache 2.0 | Local privacy, incremental indexing |
| Sweep AI | Dependency graph (root + 1-degree expansion) | SaaS agent | No | SaaS | Autonomous issue resolution |
| Aider | PageRank-ranked AST map (tree-sitter) | CLI agent | Yes | MIT | Small-medium repos, CLI workflow |
One architectural decision deserves specific attention: Sourcegraph built an embeddings-based retrieval system, found it failed at scale across 100,000+ repositories, and replaced it with BM25 ranking combined with their native code graph. Their stated reasons: privacy constraints prevented sending code to third parties, accuracy degraded beyond a certain repository count, and maintenance overhead was unsustainable. They chose structural traversal over semantic similarity.
I will address the counterpoint to this decision directly below.
The Experiments
All experiments use langchain-ai/langchain, specifically libs/core and libs/langchain - 1,900+ Python files, publicly available, reproducible by any reader. LangChain was chosen deliberately: its architecture places abstract base classes in langchain_core with implementations spread across hundreds of files in langchain. Structural questions require traversing three or more abstraction layers. This is where graph tools should have a clear advantage.
Five test tasks were defined before running any experiment - all relational questions that require structural knowledge of the codebase:
- Invocation chain: Trace the full call chain when
RunnableSequence.invoke()is called - name every class, method, and module in order. - Inheritance surface: Find every class across the codebase that inherits from
BaseRetriever. - Breaking change propagation: Identify every file that must change if
BaseMessagegains a new required field. - Circular import detection: Find any circular import dependencies across the
langchain_coremodule graph. - Implementation inconsistency: Some retrievers override
_get_relevant_documents(), others override_aget_relevant_documents(). Identify which pattern is canonical and whether deviations are documented.
Experiment 1: Graphify on LangChain
Graphify was installed via uv tool install graphifyy and run against libs/core (365 files) using a local Ollama llama3 8B model - no external API, zero cost. Build time: approximately two minutes.
Graph output: 7,876 nodes, 24,035 edges, 270 communities.
Graphify includes a benchmark command measuring token reduction versus naive full-corpus inclusion:
| Metric | Result |
|---|---|
| Naive corpus (all files) | ~525,066 tokens |
| Average tokens per graph query | ~14,360 tokens |
| Measured reduction | 36.6x average |
| Range across query types | 17.2x - 114.6x |
The vendor claims 71.5x. The measured result on this codebase is 36.6x. Both numbers are accurate - the vendor benchmarks against their highest-reduction query types on larger codebases. The actual reduction on a varied task set is lower. 36.6x is still a real and meaningful reduction. It is also the honest number to plan around.
The range across query types is the more useful signal: "what are the core abstractions" gets 114.6x reduction because the graph's community structure answers it in a handful of nodes. "What connects the data layer to the API" gets 17.2x because it requires traversing more of the graph. Token reduction is query-type-dependent, not a flat multiplier.
Accuracy on the five defined tasks:
| Task | Score | Notes |
|---|---|---|
| 1. RunnableSequence.invoke() chain | 3/5 | Right classes found; test code noise mixed in; no clean ordered chain produced |
| 2. BaseRetriever subclasses | 2/5 | 385 nodes returned; BaseRetriever found correctly; specific subclasses not surfaced |
| 3. BaseMessage change propagation | 1/5 | Ambiguous node: tool resolved "BaseMessage" to agents.py:L100, not messages/base.py |
| 4. Circular import detection | 1/5 | Query latched on the Graph class; graph traversal tools cannot detect cycles |
| 5. Retriever pattern inconsistency | 0/5 | Query matched the regex Pattern class; entirely wrong context returned |
| Total | 7/25 (28%) |
Task 3's failure mode reveals the taxonomy distinction in practice. When asked about BaseMessage, the tool resolved to the wrong node - it picked the reference in agents.py:L100 rather than the canonical class definition in messages/base.py. The graph has ambiguous nodes: the same name appears in multiple files, and the tool selects by degree centrality rather than by canonical definition. A true knowledge graph with namespace-qualified typed schema handles this by design. A dependency graph does not have a namespace layer, so it resolves ambiguity by graph centrality - which is sometimes wrong.
Experiment 2: Structured Summary Baseline
Before concluding that graph tools are the answer, I ran a comparison that most evaluations skip: a well-crafted structured markdown summary of the codebase, used as the sole context for the same five tasks.
The summary covered the module map, inheritance hierarchy, the RunnableSequence invocation chain, BaseMessage fields and propagation surface, BaseRetriever canonical pattern, and import structure. Total cost: 861 tokens - fixed upfront, not per-query.
| Task | Score | Notes |
|---|---|---|
| 1. RunnableSequence.invoke() chain | 5/5 | Documented explicitly: PromptTemplate - BaseChatModel._generate() - StrOutputParser |
| 2. BaseRetriever subclasses | 2/5 | "~40 classes in libs/langchain" - gives count and pattern, not the list |
| 3. BaseMessage change propagation | 5/5 | Explicitly listed all six impact areas plus ~50 test files |
| 4. Circular import detection | 5/5 | States the strict dependency direction; confirms no circular imports in core |
| 5. Retriever pattern inconsistency | 4/5 | Explains canonical pattern and why async override exists; no specific deviating files listed |
| Total | 21/25 (84%) |
The confound: I wrote this summary with the five test tasks already defined. A real engineer writes a codebase summary without knowing what questions will be asked next month. The 84% accuracy reflects what a targeted, task-aware summary achieves - not what a general-purpose summary would achieve on questions it was not written to anticipate.
The structured summary is a curated query cache. It performs well on the questions it was designed to answer and degrades immediately on novel questions. The dependency graph is a compound asset - it can answer arbitrary structural questions the summary never anticipated, and its value grows as the codebase and team scale.
Experiments 3 and 4: Documented Methodology
Two further experiments are documented here for reproducibility. Results will be published when completed; the methodology is included now so any reader can run them independently against the same codebase.
Experiment 3 - Sourcebot: Deploy via Docker (docker run -v $(pwd)/config.json:/etc/sourcebot/config.json sourcebot/sourcebot:latest), index the LangChain repository, connect via MCP to Claude, and run the same five tasks. Sourcebot's differentiator is natural language search across a code index rather than graph traversal - this tests whether NL search achieves comparable accuracy to property graph traversal on structural questions, and at what setup overhead.
Experiment 4 - Sourcegraph Cody vs plain Claude Code: Install the Cody VS Code extension against the same LangChain repository. Run the five tasks with Cody, then repeat with plain Claude Code (no graph, cold context). Record accuracy per task, time to answer, and hallucination count. This is the most direct comparison of dynamic retrieval (Cody's BM25 + code graph, constructed per query) versus no structural index at all.
What the Data Actually Says
Scope note: the quantitative results below come from two completed experiments, Graphify on LangChain core (365 files), and a structured summary baseline on the same five tasks. The tool recommendations in the following sections are informed by those results plus documented tool architectures and published research (LocAgent, RIG, CodexGraph), not from direct benchmarks of Sourcebot, Cody, Continue.dev, or Aider. Experiments 3 and 4 will add Sourcebot and Cody data when complete. The architectural reasoning holds regardless; the comparative rankings between specific tools are directional until those experiments close.
Two things are simultaneously true from the completed experiments:
Token reduction is real. 36.6x average on a 365-file codebase, measured independently of vendor claims. For large codebases queried frequently, this is material - both in cost and in latency. The reduction scales with query abstraction: architectural questions get the highest multiplier, cross-layer traversal questions get a lower one.
Accuracy on complex semantic queries is the current limitation. 28% on five defined relational tasks is not a passing score for a tool positioned as a primary context layer. The failure modes are specific: ambiguous node resolution (same class name in multiple files), no cycle detection, semantic query mismatch on terminology. These are solvable engineering problems, not fundamental limitations of the graph approach.
The practical conclusion: graph tools today are best used as context enrichment alongside targeted file reads, rather than as a standalone context replacement. The token reduction applies to the graph query layer; you still read specific files for tasks that require code-level detail. The graph tells you which files to read. That is still enormously valuable.
The structured summary result is not an argument against graphs. It is an argument for matching context type to query type. Stable, well-understood query patterns over a stable architecture - structured summaries are efficient and sufficient. Growing codebases, diverse teams, novel questions that no one anticipated when writing the last summary - that is where the compound value of a maintained graph becomes defensible.
The Industry Is Split - and Both Sides Are Right
An honest treatment of this topic requires confronting a real contradiction in the current tool landscape.
Sourcegraph built an embeddings-based retrieval system, concluded it failed at scale, and replaced it with BM25 ranking combined with a structural code graph. Their reasoning: embeddings required sending code to third parties, accuracy degraded beyond 100,000 repositories, and maintenance overhead was unsustainable. They chose structural traversal over semantic similarity.
GitHub shipped a new Copilot embedding model in 2025 with a 37.6% improvement in retrieval quality, 2x throughput, and 8x memory reduction for indexing. They chose the opposite direction - investing heavily in semantic similarity at scale.
Both decisions are defensible for their context. Sourcegraph operates across enterprise repositories at a scale where privacy constraints and maintenance cost are decisive. GitHub has the infrastructure to run embeddings at that scale and a user base that justifies the investment.
For your team, the implication is not "pick a side." It is that graph traversal and embedding-based retrieval answer different query types. Structural questions - dependency chains, call graphs, inheritance trees, change propagation - favor graph traversal. Similarity questions - "find code that does something like this", "find examples of this pattern" - favor embeddings. A mature AI coding stack needs both. Most teams currently have neither.
Recommended Stack by Repo Size
These recommendations reflect tested tool capabilities and documented integrations. No combination is recommended here that has not been verified to work or is not explicitly documented as compatible.
Under 100 files: Aider's repo map is sufficient. Zero indexing overhead; PageRank-scored AST gives the agent the most structurally important symbols without a full graph. Pair with Continue.dev for semantic search if needed.
100 to 500 files: Continue.dev (local embeddings + tree-sitter AST) covers most daily queries. Incremental indexing handles fast-moving codebases. Add Sourcebot for natural language search across multiple repositories if your team spans more than one codebase.
500+ files, single repository: Graphify for the structural dependency graph, queried per session. The 36.6x token reduction makes the build cost worthwhile above this threshold. Combine with Continue.dev for semantic retrieval on similarity questions.
Enterprise, multi-repository: Sourcegraph Cody. Cross-repo code graph, IDE-native, dynamic context construction per query without a pre-indexed graph to maintain. The architectural decision to abandon embeddings reflects deliberate thinking about what works at enterprise scale.
Autonomous agents: Sweep AI. Purpose-built for agent-driven issue resolution with a dependency graph expansion strategy (root nodes expanded to one-degree neighbours). Not a general-purpose tool; specifically effective for the "AI resolves a GitHub issue" workflow.
The pattern that runs through all of these: separate structural understanding (dependency graph, AST map) from semantic retrieval (embeddings, BM25). They answer different query types. Teams building effective AI coding infrastructure wire both together.
Where This Goes
The academic research points consistently toward a shift in how agents interact with codebases. LocAgent's agents navigate using three operations - SearchEntity, TraverseGraph, and RetrieveEntity - where the graph is not context passed to the LLM but the navigation substrate the agent moves through. CodexGraph puts this into a property graph database with a typed schema (MODULE, CLASS, FUNCTION nodes; CONTAINS, CALLS, INHERITS edges) and demonstrates that graph-structured retrieval outperforms similarity-based retrieval on complex multi-file tasks.
The shift is from "give the agent the file" to "let the agent traverse the graph." That is already in production at teams using these tools. The engineering leaders who instrument this architecture now will have a structural advantage as agentic coding matures - not because they moved early on a trend, but because a well-maintained code graph is a compound asset. It gets more useful as the codebase grows, as the team scales, and as query patterns diversify beyond what any manually maintained summary covers.
The current tools are early-stage implementations of a sound architectural pattern. The token reduction is real. The accuracy ceiling for complex semantic queries is a current limitation, not a fundamental constraint. The teams that understand the difference between a dependency graph and a knowledge graph, and choose tools accordingly, will extract genuine value from both.
Sources
- Andrej Karpathy, "context engineering" (verified) - x.com/karpathy/status/1937902205765607626
- LocAgent: Graph-Guided LLM Agents for Code Localization (2025) - arxiv.org/abs/2503.09089
- CodexGraph: Bridging LLMs and Code Repositories via Graph Databases - arxiv.org/abs/2408.03910
- Repository Intelligence Graph (RIG) - arxiv.org/abs/2601.10112
- How Cody Understands Your Codebase (Sourcegraph) - sourcegraph.com/blog/how-cody-understands-your-codebase
- GitHub Copilot New Embedding Model (2025) - github.blog
- Graphify - graphify.net
- Sourcebot - sourcebot.dev
- Aider Repo Map - aider.chat
Working through the challenges in this post? I help engineering leaders and CTOs navigate complex technical decisions and scale high-performing teams. Schedule a consultation →